Transformer 架構介紹
1. 引言
自2017年Google團隊發表里程碑論文《Attention Is All You Need》以來,Transformer架構徹底革新了自然語言處理(NLs)領域。在此之前,循環神經網絡(RNN)、長短期記憶網絡(LSTM)和門控循環單元(GRU)一直是處理序列數據的主流方法,但這些模型存在訓練緩慢且難以並行化的固有缺陷。Transformer的革命性在於完全捨棄了循環結構,而僅依靠注意力機制(Attention Mechanism)來建模序列數據之間的依賴關係。
這一突破不僅帶來了性能的顯著提升,還極大地加快了訓練速度。從機器翻譯這一最初的應用場景,到後續的BERT、GPT、T5等模型,Transformer架構已經成為現代NLP的基石,並逐漸擴展到計算機視覺、音頻處理等多個領域。

在深入理解Transformer之前,我們有必要認識到它解決了什麼問題: 1. 長距離依賴問題:RNN類模型在處理長序列時,梯度消失/爆炸問題導致難以捕捉遠距離信息 2. 串行計算問題:RNN的計算天然是序列化的,難以充分利用現代GPU/TPU的並行計算能力 3. 固定長度表示問題:傳統編碼-解碼架構通常將整個輸入壓縮為固定長度向量,信息瓶頸明顯
本文將系統且深入地講解Transformer的基本原理、架構組成、數學基礎以及實際應用,幫助讀者真正掌握這一革命性的深度學習架構。
2. Transformer架構概覽
Transformer採用了編碼器-解碼器(Encoder-Decoder)架構,這種架構在機器翻譯等序列到序列(Sequence-to-Sequence)任務中非常常見。然而,與傳統的編碼器-解碼器模型不同,Transformer的核心創新在於完全依靠注意力機制來處理序列數據。
2.1 整體架構
原始Transformer包含六層編碼器和六層解碼器。每個編碼器層由兩個子層組成:多頭自注意力機制(Multi-Head Self-Attention)和前饋神經網絡(Feed-Forward Neural Network)。每個解碼器層則包含三個子層:遮蔽的多頭自注意力(Masked Multi-Head Self-Attention)、多頭編碼器-解碼器注意力(Multi-Head Encoder-Decoder Attention)以及前饋神經網絡。

2.2 核心特點與創新
Transformer的核心特點包括:
並行處理能力:不同於RNN的序列處理方式,Transformer能夠一次性處理整個序列的所有元素,大大提高了訓練效率。這是因為自注意力機制允許每個位置直接與所有其他位置進行交互,而不需要按時間步驟迭代。在實際訓練中,這意味著可以充分利用GPU/TPU的並行計算能力,將訓練時間從幾週縮短到幾天或更短。
長距離依賴建模:通過自注意力機制,Transformer可以直接建模序列中任意兩個位置之間的關係,而不受距離限制。在LSTM等循環模型中,遠距離信息需要經過多次狀態傳遞,容易衰減或丟失;而在Transformer中,第一個詞和最後一個詞之間的關係可以像相鄰詞那樣直接計算,有效解決了長距離依賴問題。
例如,在句子"The animal that was chased by the dogs, which were very aggressive, was a small rabbit"中,傳統RNN可能難以將"was"與遠處的主語"animal"關聯起來,而Transformer能夠通過自注意力直接建立這種連接。
位置編碼:由於Transformer沒有循環或卷積結構,它無法天然地理解序列順序。為了彌補這一缺陷,研究者引入了位置編碼(Positional Encoding),將位置信息直接編碼到輸入表示中。這使得模型能夠區分不同位置的相同詞,理解序列的順序關係。
多頭注意力機制:傳統注意力機制專注於單一的表示子空間,而多頭注意力允許模型同時關注不同表示子空間的信息模式,大大增強了模型的表現力。例如,某些注意力頭可能專注於句法關係,而其他頭則專注於語義關係。
殘差連接與層歸一化:Transformer大量使用殘差連接(Residual Connection)和層歸一化(Layer Normalization)技術,這不僅有助於訓練非常深的網絡,還能緩解梯度消失問題,提高訓練穩定性。
2.3 信息流動路徑
讓我們追蹤Transformer中的信息流動路徑,以便更好地理解它的工作原理:
輸入處理階段:
- 輸入序列首先通過嵌入層(Embedding Layer)轉換為密集向量表示
- 位置編碼被添加到嵌入向量中,注入位置信息
- 結果輸入到編碼器堆疊的底層
編碼器階段:
- 在每一層編碼器中,自注意力機制允許每個位置關注輸入序列的所有位置
- 注意力的輸出經過一個前饋網絡進一步轉換
- 每個子層都應用殘差連接和層歸一化
- 信息從底層向頂層傳遞,逐步提取更抽象的特徵
解碼器階段:
- 解碼器以類似方式處理目標序列,但使用遮蔽來防止看到未來信息
- 編碼器-解碼器注意力層允許解碼器關注輸入序列的所有位置
- 頂層解碼器輸出經過線性變換和softmax層生成概率分布
3. 自注意力機制(Self-Attention)
自注意力機制是Transformer的核心創新,它使模型能夠關注輸入序列的不同部分並捕捉元素間的關係,而不受距離限制。
3.1 直觀理解
想象一下,當我們閱讀長文本時,大腦會自動將當前單詞與之前出現的相關單詞關聯起來,以便理解上下文。例如,在句子「The cat sat on the mat because it was comfortable」中,我們能夠理解「it」指代的是「mat」而不是「cat」,這就是一種注意力機制。
自注意力機制模擬了這種認知過程,它允許模型在處理每個位置時,自動「關注」序列中的其他相關位置。與傳統的固定窗口注意力不同,自注意力可以靈活地關注任何位置,不受距離限制。

3.2 數學原理與計算步驟
自注意力機制的計算過程可分為以下詳細步驟:
線性投影生成查詢、鍵和值: 輸入矩陣 $X \in \mathbb{R}^{n \times d}$($n$是序列長度,$d$是嵌入維度)首先被投影為三種不同的表示:
$$Q = XW^Q, K = XW^K, V = XW^V$$
其中 $W^Q, W^K, W^V \in \mathbb{R}^{d \times d_k}$ 是可學習的權重矩陣。$Q$代表查詢(Query),$K$代表鍵(Key),$V$代表值(Value)。直觀上,查詢表示「我想要什麼信息」,鍵表示「我有什麼信息」,值表示「我傳遞什麼信息」。
計算注意力分數: 查詢和鍵通過點積操作計算相似度(注意力分數):
$$S = QK^T$$
結果是一個 $n \times n$ 的矩陣,其中 $S_{ij}$ 表示第 $i$ 個位置對第 $j$ 個位置的注意力分數。
縮放: 為了防止點積結果過大導致softmax函數梯度消失,注意力分數需要進行縮放:
$$S_{scaled} = \frac{S}{\sqrt{d_k}} = \frac{QK^T}{\sqrt{d_k}}$$
除以 $\sqrt{d_k}$ 是因為當 $d_k$ 較大時,點積的方差會增大,可能導致softmax函數落入梯度極小的區域。
掩碼(可選): 在解碼器的自注意力中,為了防止模型看到未來信息,需要應用掩碼:
$$S_{masked} = S_{scaled} + M$$
其中 $M$ 是掩碼矩陣,對應於未來位置的元素被設為 $-\infty$(實際實現中通常是一個非常大的負數,如 -1e9)。
Softmax歸一化: 注意力分數通過softmax函數歸一化,將其轉換為概率分布:
$$A = \text{softmax}(S_{masked}) = \frac{\exp(S_{masked})}{\sum \exp(S_{masked})}$$
歸一化確保所有注意力權重的總和為1,形成一個概率分布。
加權求和: 最後,用歸一化後的注意力權重對值矩陣進行加權求和:
$$O = AV$$
輸出 $O$ 是一個 $n \times d_k$ 的矩陣,每一行代表對應位置的上下文感知表示。
完整的自注意力計算可以簡潔地表示為:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
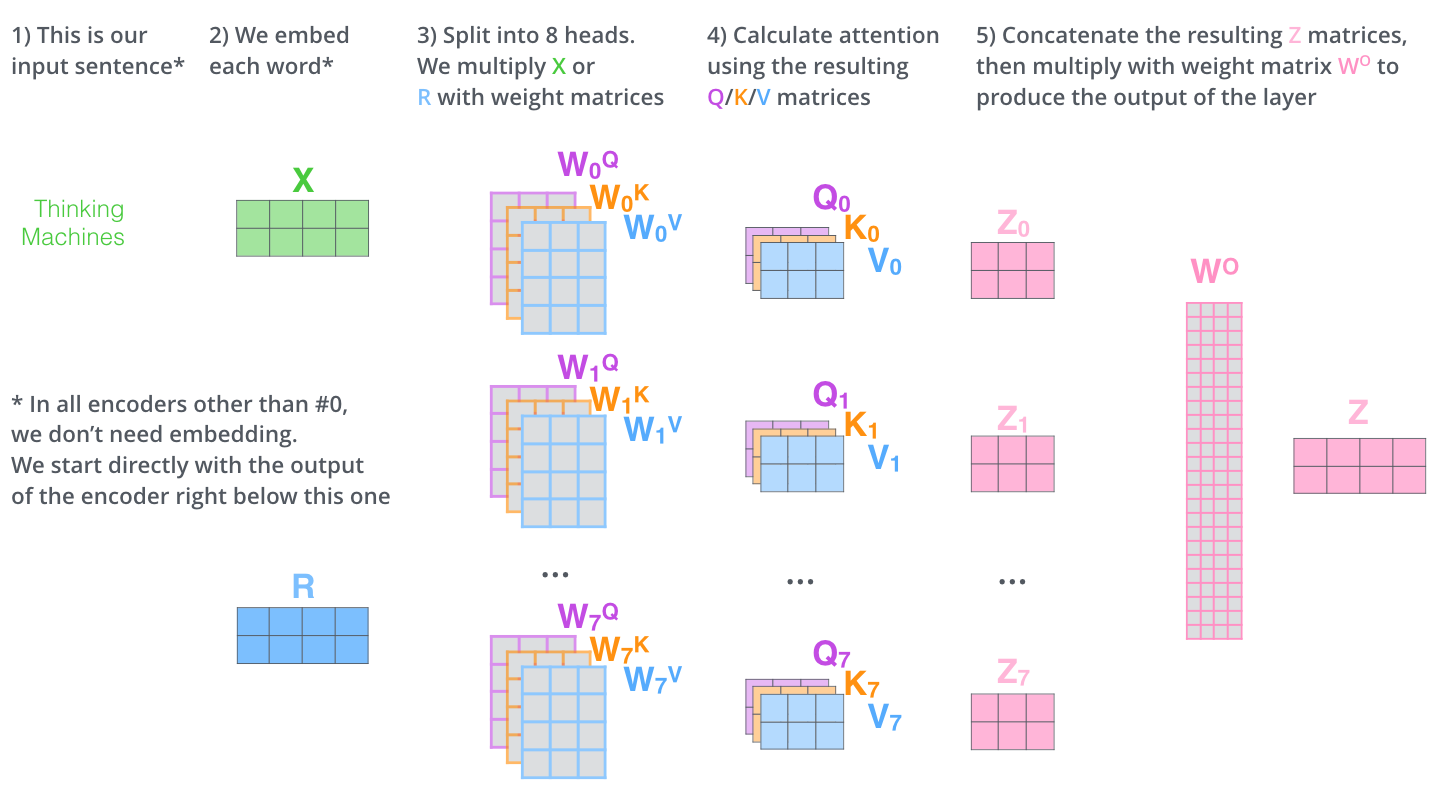
3.3 詳細的矩陣運算示例
為了更具體地理解自注意力的計算過程,讓我們通過一個小型示例進行說明。考慮一個由3個詞組成的句子,每個詞的嵌入維度為4:
輸入矩陣 $X \in \mathbb{R}^{3 \times 4}$: $$X = \begin{bmatrix} x_1^1 & x_1^2 & x_1^3 & x_1^4 \ x_2^1 & x_2^2 & x_2^3 & x_2^4 \ x_3^1 & x_3^2 & x_3^3 & x_3^4 \end{bmatrix}$$
假設投影維度 $d_k = 2$,權重矩陣為: $$W^Q = \begin{bmatrix} w_{11}^Q & w_{12}^Q \ w_{21}^Q & w_{22}^Q \ w_{31}^Q & w_{32}^Q \ w_{41}^Q & w_{42}^Q \end{bmatrix}, W^K = \begin{bmatrix} w_{11}^K & w_{12}^K \ w_{21}^K & w_{22}^K \ w_{31}^K & w_{32}^K \ w_{41}^K & w_{42}^K \end{bmatrix}, W^V = \begin{bmatrix} w_{11}^V & w_{12}^V \ w_{21}^V & w_{22}^V \ w_{31}^V & w_{32}^V \ w_{41}^V & w_{42}^V \end{bmatrix}$$
計算 $Q, K, V$: $$Q = XW^Q \in \mathbb{R}^{3 \times 2}, K = XW^K \in \mathbb{R}^{3 \times 2}, V = XW^V \in \mathbb{R}^{3 \times 2}$$
計算注意力分數和最終輸出: $$S = QK^T \in \mathbb{R}^{3 \times 3}$$ $$S_{scaled} = \frac{S}{\sqrt{2}}$$ $$A = \text{softmax}(S_{scaled}) \in \mathbb{R}^{3 \times 3}$$ $$O = AV \in \mathbb{R}^{3 \times 2}$$
3.4 自注意力的實例分析
讓我們通過一個具體的自然語言例子來理解自注意力機制:
考慮句子「The dog chased the cat, but it was friendly.」
在處理這個句子時,當模型關注「it」這個詞時,自注意力機制允許模型分配不同的注意力權重給句子中的其他詞。在理想情況下,「it」應該與「dog」有較高的注意力連接,因為從上下文可以推斷「it」指代的是「dog」。
在實際的Transformer模型中,不同的注意力頭可能捕捉不同類型的關係: - 頭1可能關注代詞指代關係,給予「dog」高注意力 - 頭2可能關注句法關係,注意「it」和「was」之間的連接 - 頭3可能關注語義相關性,連接「it」和「friendly」
這種多角度的關注能力使Transformer能夠全面理解文本的各種語言特性。
4. 多頭注意力機制(Multi-Head Attention)
為什麼單一的注意力機制不夠?想象一下,如果我們只有一種方式來看待一段文本,我們可能會錯過其中的微妙關係。多頭注意力機制通過「多角度」同時關注輸入,大大增強了模型的表達能力。
4.1 動機與直觀理解
Single-Head Attention 只能捕捉一種關係模式,而實際上,序列元素之間可能存在多種不同類型的關係。例如,在自然語言中,詞與詞之間可能同時存在句法關係、語義關係、共指關係等。
Multi-Heads Attention 允許模型同時以不同的方式「觀察」輸入序列,就像人類在閱讀文本時會從多個角度(語法、語義、邏輯等)理解內容一樣。通過在不同的表示子空間中執行多個並行的注意力函數,模型能夠捕捉到更豐富的信息。
4.2 數學公式與計算流程
多頭注意力機制的計算可以分為以下詳細步驟:
線性投影: 與單頭注意力類似,首先將輸入 $X$ 投影到不同的子空間。不同的是,多頭注意力為每個頭創建不同的投影矩陣:
$$Q_i = XW_i^Q, K_i = XW_i^K, V_i = XW_i^V \quad \text{for} \quad i \in {1, 2, ..., h}$$
其中 $h$ 是頭的數量,$W_i^Q, W_i^K, W_i^V \in \mathbb{R}^{d \times d_k}$ 是第 $i$ 個頭的投影矩陣。通常 $d_k = d/h$,這樣多頭的總參數量與單頭相同。
並行計算注意力: 對每個頭獨立地計算注意力:
$$\text{head}_i = \text{Attention}(Q_i, K_i, V_i) = \text{softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_k}}\right)V_i$$
拼接與線性變換: 將所有頭的輸出拼接起來,然後通過一個線性變換:
$$\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, ..., \text{head}_h)W^O$$
其中 $W^O \in \mathbb{R}^{hd_k \times d}$ 是輸出投影矩陣。
原始Transformer使用了 $h = 8$ 個頭,每個頭的維度為 $d_k = 64$,這意味著模型可以學習8種不同的注意力模式。
4.3 多頭相對於單頭的優勢
多頭注意力機制相比單頭注意力有以下顯著優勢:
增強表達能力:不同的頭可以學習關注不同類型的模式和關係,大大豐富了模型的表達能力。
增加穩定性:多頭機制可以被視為一種集成學習,多個頭的結果被合併,減少了過擬合風險,提高了模型的穩定性。
提供可解釋性:分析不同頭的注意力模式可以幫助解釋模型的決策過程。例如,一些頭可能專注於句法結構,而其他頭則可能專注於語義關係。
4.4 多頭注意力的實際例子
讓我們詳細分析一個具體例子。假設有一個句子「The student read the book because it had important information」,使用4個注意力頭處理。
- 頭1(語法關係):可能在「read」和「student」之間建立強連接,捕捉主語-動詞關係
- 頭2(語義關係):可能連接「book」和「information」,捕捉相關概念
- 頭3(代詞指代):可能強烈關注「it」和「book」之間的連接,解決指代問題
- 頭4(因果關係):可能強調「because」與前後成分的連接,理解因果關係
通過這種多角度的關注,模型能夠全面理解句子的結構和含義。
5. 位置編碼(Positional Encoding)
5.1 位置信息的重要性
在自然語言處理中,序列中單詞的順序對於理解語義至關重要。考慮以下兩個句子: - 「貓追狗」 - 「狗追貓」
這兩個句子包含完全相同的三個詞,但由於順序不同,它們的含義截然不同。傳統的RNN類模型通過依序處理輸入來隱式地捕捉位置信息。然而,Transformer的自注意力機制是並行計算的,沒有內在的順序性,因此需要顯式地將位置信息加入到輸入表示中。
5.2 正弦余弦位置編碼的數學原理
原始Transformer採用的位置編碼基於正弦和余弦函數,對於位置 $pos$ 和維度 $i$,位置編碼定義為:
$$PE_{(pos, 2i)} = \sin(pos/10000^{2i/d_{model}})$$ $$PE_{(pos, 2i+1)} = \cos(pos/10000^{2i/d_{model}})$$
其中,$d_{model}$ 是模型的嵌入維度,$i$ 範圍從 $0$ 到 $d_{model}/2-1$。
這一選擇看似複雜,實際上有其深刻的數學考慮:
周期性:正弦和余弦函數是周期性的,使得模型可以泛化到訓練中未見過的序列長度。
唯一性:每個位置獲得一個唯一的編碼向量,不同位置的編碼之間存在可測量的差異。
相對位置信息:任意固定偏移的位置之間的相對位置可以通過線性變換來表示。這一特性來自於三角函數的加法定理:
$$\sin(\alpha + \beta) = \sin(\alpha)\cos(\beta) + \cos(\alpha)\sin(\beta)$$ $$\cos(\alpha + \beta) = \cos(\alpha)\cos(\beta) - \sin(\alpha)\sin(\beta)$$
這意味著位置 $pos+k$ 的編碼可以表示為位置 $pos$ 的編碼的線性函數,使得模型更容易學習關於相對位置的依賴關係。
頻率變化:不同維度使用不同頻率的正弦波,從而創建多尺度的位置表示。較低的維度(較小的 $i$ 值)對應較低的頻率,變化較慢,可以捕捉長距離依賴;較高的維度對應較高的頻率,變化較快,可以捕捉短距離的細微差別。
5.3 位置編碼的可視化與理解

如上圖所示,位置編碼在不同維度上呈現出不同頻率的波動。較低維度(圖的左側)變化緩慢,而較高維度(圖的右側)變化迅速。這種設計允許模型學習對不同尺度的位置關係的依賴。
5.4 位置編碼的應用
在實際應用中,位置編碼向量 $PE$ 通常被加到輸入嵌入 $E$ 中,得到位置感知的輸入表示:
$$X = E + PE$$
這種加法操作而非連接操作的選擇是為了保持嵌入維度不變,簡化後續的注意力計算。
值得注意的是,位置編碼只在輸入層添加一次,而不是在每一層都添加。這是因為注意力機制可以傳遞位置信息,使得位置信息在整個網絡中流動。
5.5 其他位置編碼方案
除了正弦余弦位置編碼,研究者還提出了多種替代方案:
可學習的位置編碼:不預先定義固定的編碼函數,而是將位置編碼作為可學習的參數,讓模型自行學習最優的位置表示。BERT等模型採用了這種方法。
相對位置編碼:不是為每個絕對位置分配一個向量,而是直接編碼元素之間的相對距離。例如,Transformer-XL和T5模型採用了這種方法。
旋轉位置編碼(RoPE):在複數域中通過旋轉操作來編碼位置信息,這種方法近期在許多大型語言模型中得到應用,如GPT-3.5、GPT-4等。
每種位置編碼方案都有其優缺點,選擇哪種方法通常取決於具體任務和模型架構。
6. 編碼器和解碼器結構
Transformer的編碼器和解碼器是設計用來處理不同階段的信息處理:編碼器專注於理解輸入,而解碼器專注於生成輸出。讓我們詳細分析它們的結構和工作原理。
6.1 編碼器(Encoder)詳解
6.1.1 編碼器的總體架構
原始Transformer使用了6個相同的編碼器層堆疊而成。每個編碼器層包含兩個主要子層:
- 多頭自注意力層
- 前饋神經網絡層
每個子層都應用了兩個關鍵技術: - 殘差連接(Residual Connection):防止深層網絡中的梯度消失問題 - 層歸一化(Layer Normalization):加速訓練並提高穩定性
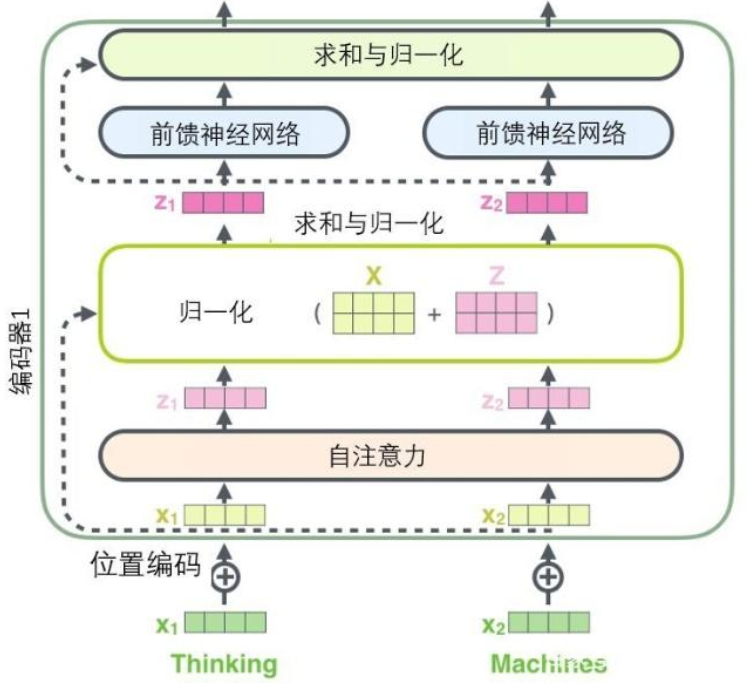
6.1.2 殘差連接和層歸一化
Transformer中的每個子層輸出可以表示為:
$$\text{LayerNorm}(x + \text{Sublayer}(x))$$
其中 $\text{Sublayer}(x)$ 是子層自身的函數(如自注意力或前饋網絡),$\text{LayerNorm}$ 是層歸一化操作。
層歸一化對每個樣本的各個特徵進行標準化,使其均值為0,方差為1:
$$\text{LayerNorm}(x) = \gamma \cdot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta$$
其中,$\mu$ 和 $\sigma$ 分別是樣本特徵的均值和標準差,$\gamma$ 和 $\beta$ 是可學習的縮放和偏移參數,$\epsilon$ 是一個小常數,防止除零。
殘差連接和層歸一化的組合對於訓練深度Transformer至關重要,它們共同作用: - 緩解梯度消失問題 - 加速網絡收斂 - 提高訓練穩定性 - 增強特徵傳遞
6.1.3 前饋神經網絡
每個編碼器層的第二個子層是一個前饋神經網絡,由兩個線性變換和一個ReLU激活函數組成:
$$\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2$$
這個前饋網絡對每個位置獨立應用相同的變換,可以視為一個位置級別的特徵轉換。原始Transformer的內部維度是2048,而輸入/輸出維度是512,這意味著前饋網絡首先將維度擴展4倍,然後再投影回原來的維度。
擴展內部維度的目的是增加模型的表達能力,讓它能夠學習更複雜的非線性轉換。前饋網絡本質上是在注意力機制捕捉的上下文信息之上,進一步提取更深層次的特徵。
6.2 解碼器(Decoder)詳解
6.2.1 解碼器的總體架構
Transformer的解碼器同樣堆疊了6個相同的層,但每個解碼器層包含三個主要子層:
- 遮蔽的多頭自注意力層
- 編碼器-解碼器多頭注意力層
- 前饋神經網絡層
同樣,每個子層都應用了殘差連接和層歸一化。
6.2.2 遮蔽機制(Masking)
解碼器的第一個子層使用了遮蔽的自注意力機制,這是為了確保預測位置 $i$ 的輸出只依賴於已知的輸出(即位置小於 $i$ 的輸出)。這一點至關重要,因為在訓練過程中,解碼器可以看到整個目標序列,但在推理過程中,模型需要一次生成一個輸出。
遮蔽是通過將未來位置的注意力分數設為負無窮(實際實現中通常是一個非常大的負數,如-1e9)來實現的:
$$S_{masked} = S + M$$
其中 $M$ 是遮蔽矩陣,對於位置 $(i, j)$:
$$M_{ij} = \begin{cases} 0 & \text{if } j \leq i \ -\infty & \text{if } j > i \end{cases}$$
這樣,在softmax之後,未來位置的注意力權重將變為0,確保模型不會「偷看」未來的信息。

6.2.3 編碼器-解碼器注意力機制
解碼器的第二個子層是編碼器-解碼器注意力機制,它允許解碼器關注輸入序列的各個部分。在這一層中: - 查詢(Q)來自上一層解碼器的輸出 - 鍵(K)和值(V)來自編碼器的最終輸出
這種設計使得解碼器能夠在生成每個輸出時,關注到輸入序列的相關部分。例如,在機器翻譯任務中,這允許模型在生成每個目標語言詞時,關注原始源語言句子的相關部分。
編碼器-解碼器注意力的計算與自注意力類似,但不同的是它不需要遮蔽,因為解碼器可以完全訪問輸入序列的所有位置:
$$\text{CrossAttention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
這種跨模態的注意力機制是序列到序列模型的關鍵,它將編碼器的理解能力與解碼器的生成能力橋接起來。
6.2.4 最終線性層和Softmax
解碼器堆疊的輸出經過一個線性層投影到詞彙表維度,然後通過softmax函數轉換為下一個詞的概率分布:
$$P(y_t | y_{ 其中 $D$ 是輸出投影矩陣,$h_t$ 是解碼器最後一層的輸出,$b$ 是偏置項。在原始Transformer中,輸出投影矩陣 $D$ 與輸入嵌入矩陣共享權重,這有助於減少參數量並提高性能。 讓我們總結一下編碼器和解碼器的數學表達: 對於編碼器層 $i$:
$$E_{i}' = \text{LayerNorm}(E_i + \text{MultiHeadAttention}(E_i, E_i, E_i))$$
$$E_{i+1} = \text{LayerNorm}(E_{i}' + \text{FFN}(E_{i}'))$$ 對於解碼器層 $i$:
$$D_{i}' = \text{LayerNorm}(D_i + \text{MaskedMultiHeadAttention}(D_i, D_i, D_i))$$
$$D_{i}'' = \text{LayerNorm}(D_{i}' + \text{MultiHeadAttention}(D_{i}', E_{final}, E_{final}))$$
$$D_{i+1} = \text{LayerNorm}(D_{i}'' + \text{FFN}(D_{i}''))$$ 這些表達式簡潔地概括了信息如何在Transformer中流動。 Transformer架構自問世以來,已被應用於眾多NLP任務,並衍生出多種變體。 原始Transformer最初設計用於機器翻譯任務,在WMT 2014英德和英法翻譯基準測試中取得了當時最先進的結果,BLEU分數分別提高了2.0和0.7點,同時訓練速度大幅增加。 具體來說,在英語到德語的翻譯任務中,原始Transformer的BLEU分數達到28.4,超過了之前基於CNN和RNN的最佳模型。這一成就證明了自注意力機制在捕捉語言間的對應關係方面的強大能力。 GPT系列模型採用了Transformer的解碼器架構,並通過自迴歸方式訓練,成為強大的文本生成模型。從2018年的GPT-1開始,到2020年的GPT-3(1750億參數),再到最新的GPT-4,這一系列模型展示了Transformer架構在大規模預訓練中的驚人潛力。 GPT模型的核心思想是通過預測下一個詞來學習語言模型,然後通過微調應用於具體任務。這種方法的成功表明,Transformer解碼器能夠通過大規模無監督學習掌握豐富的語言知識。 BERT(Bidirectional Encoder Representations from Transformers)採用了Transformer的編碼器架構,通過掩碼語言模型和下一句預測任務進行預訓練,然後在各種理解任務上微調。 BERT及其變體(如RoBERTa、ALBERT)在GLUE和SQuAD等基準測試上取得了突破性的成績。例如,在SQuAD問答任務上,BERT的F1分數達到93.2,超過了人類表現(91.2)。這表明Transformer編碼器非常適合捕捉文本的深層語義和上下文關係。 Transformer的成功不僅限於純文本任務,還擴展到了多模態領域: BERT是最具代表性的Transformer編碼器變體,它通過雙向自注意力機制和掩碼語言模型預訓練,捕捉文本的雙向上下文。 BERT的變體包括:
- RoBERTa:修改了BERT的預訓練方法,移除了下一句預測任務,使用更大的批量和更多數據
- ALBERT:通過參數共享和嵌入分解降低參數量,同時保持性能
- DistilBERT:通過知識蒸餾技術壓縮BERT,減少40%的參數量,同時保持97%的性能 GPT系列模型專注於生成能力,採用了只使用Transformer解碼器的架構:
- GPT-2:相比GPT-1增加了參數量(15億)和訓練數據,展示了更強的生成能力
- GPT-3:進一步擴大到1750億參數,展示了少樣本學習能力
- GPT-4:多模態能力顯著增強,推理能力和安全性大幅提升 為了解決Transformer的計算複雜度問題,研究者提出了多種優化方案:
- Transformer-XL:引入段級循環機制,處理長序列
- Longformer, BigBird:通過稀疏注意力機制降低複雜度
- Reformer:使用局部敏感哈希減少注意力的計算量
- Linformer:將注意力的複雜度從 $O(n^2)$ 降低到 $O(n)$
- Performer:使用核方法近似全注意力 Transformer架構的出現標誌著深度學習進入了一個新時代。它不僅改變了我們處理序列數據的方式,還為人工智能的發展提供了強大的基礎設施。從最初的機器翻譯應用,到如今支撐大型語言模型和多模態系統,Transformer已經深刻地改變了人工智能領域。 隨著研究的不斷深入和技術的持續創新,我們有理由相信,基於Transformer的模型將繼續推動人工智能向更高水平發展,為解決更複雜的問題提供更強大的工具。無論是在學術研究還是實際應用中,掌握Transformer架構的原理和應用已經成為深度學習領域的必備技能。6.3 架構的數學表達
7. 實際應用和變體
7.1 典型應用場景
7.1.1 機器翻譯
7.1.2 語言模型
7.1.3 文本理解
7.1.4 多模態任務
7.2 主要變體和演進
7.2.1 編碼器類變體(BERT系列)
7.2.2 解碼器類變體(GPT系列)
7.2.3 編碼器-解碼器變體
7.2.4 效率優化變體
8. 總結